很长一段时间以来,我都对业界数据分析里各种术语感到困惑:工作中经常会听到如“维度”、“粒度”、“尺度”和“口径”这样的词汇,起初,我以为这些都是某些深奥的专业术语,但随着时间的推移,我意识到其实它们与我们的日常生活关系密切,只是我们未曾如此系统地去认识它们。
想象一下,我们手中的数据就像一个庞大的商品仓库,这个仓库中的每一件商品都是独特的,我们如何快速准确地找到需要的商品?这时,那些“神秘”的词汇就像是我们手中的指南针和放大镜,帮助我们定位和深入观察。
那么让我们从一个数据仓库出发,开始理解各个术语吧!

维度 (Dimension)
维度指的是数据的分类特征或属性。例如,性别能够取值为:男/女/其他,我们可以通过性别的取值对人群进行分类,那么性别就是一种典型的维度;刚刚的数据仓库里的数据,我们可以从不同的角度去进行观测,观测的角度即为“维度”:多数情况下,维度的不同取值为我们提供了拆分数据的方法。
如下图所示,假设我们选取了观测属性 P,在这个数据仓库里一个有三种属性 P,分别是 A / B / C,我们从这个维度对数据进行观测,就可以把所有的数据记录分为三类。每一类里面都有很多在这个属性上被归类的“数据条”,每一个数据条也都能被归类到唯一一个确定的属性类型里(要么是 P=A,要么是 P=B,要么是 P=C)。
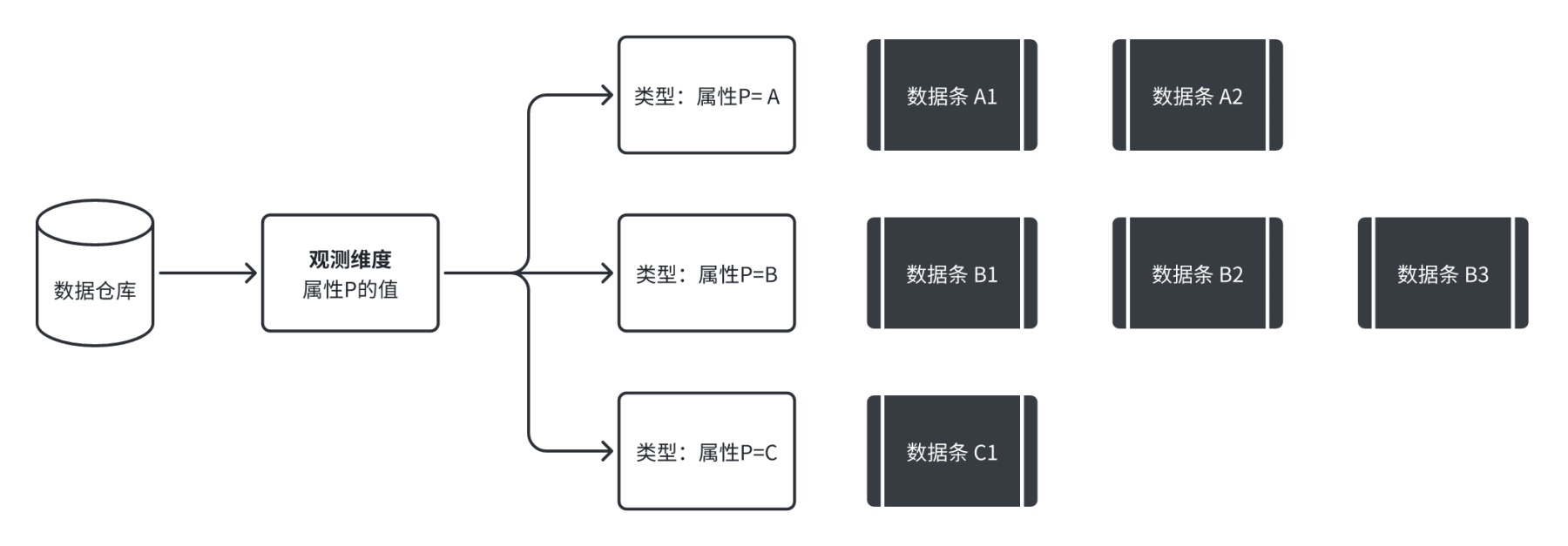
如果我们同时从不同的维度将数据进行拆分,比如同时从两个角度进行观测,就能够获取基础的分类 / 分属性分布信息,也就在结构上得到了数据透视表(又称为:数据交叉表、枢纽表、关联表、相依表)。
例如,我们想分析不同体量的客户,分别在一周的哪一天签订了订单。也就是我们经常说“按照日期 / 客户类别等维度进行透视”,在日期这个角度上观测,所有数据能够分为周一到周日的 7 天,在客户类别这个角度上观测,所有数据能分为“小型客户、中型客户、大型客户”3种类别,那么我们或许可以构建一个 7 行 ✕ 3 列的数据透视表:
| 日期 / 客户类别 | 小型客户 | 中型客户 | 大型客户 |
|---|---|---|---|
| 周一 | |||
| 周二 | |||
| 周三 | |||
| 周四 | |||
| 周五 | |||
| 周六 | |||
| 周日 |
在电商销售数据中,一些常见的维度有:
- 顾客维度:顾客的年龄、性别、地区等
- 账户维度:如账户创建日期、账户类型(普通用户、VIP 用户)等
- 商品维度:商品的类别、品牌和颜色等
度量 (Measure) / 指标 (Metric)
度量是事实表中的数值数据(数字),也就是在维度基础上衡量对应结果的值;刚刚我们在上面列出的数据透视表,们按照日期、客户类别维度进行透视之后,得到的表只有行 / 列标题,而主体部分还是空白的,这些填写在表格主体部分的数值就是度量(或者叫指标)。
指标是一种特殊的度量,通常是“被赋予了实际意义”的度量,用来衡量和跟踪业务或运营绩效的数值,在工作中,我们常制定不同的指标帮助我们理解业务表现,如“月销售额”或“日活跃用户数”。
| 日期 / 客户类别 | 小型客户 | 中型客户 | 大型客户 |
|---|---|---|---|
| 周一 | 度量值 | 度量值 | 度量值 |
| 周二 | 度量值 | 度量值 | 度量值 |
| 周三 | 度量值 | 度量值 | 度量值 |
| 周四 | 度量值 | 度量值 | 度量值 |
| 周五 | 度量值 | 度量值 | 度量值 |
| 周六 | 度量值 | 度量值 | 度量值 |
| 周日 | 度量值 | 度量值 | 度量值 |
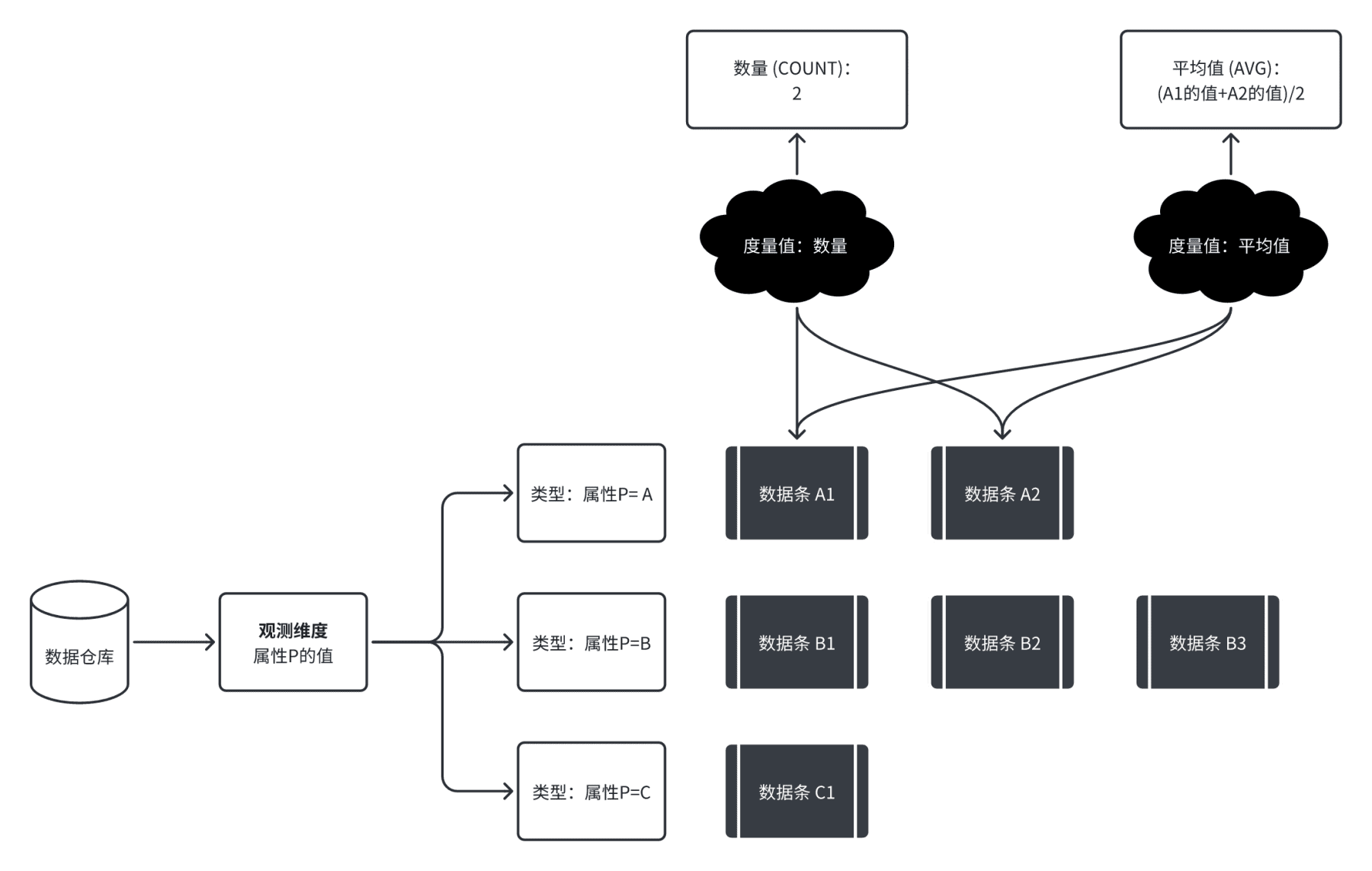
还是回到刚刚的数据仓库里的数据,我们基于维度“属性 P”进行观测后,在“属性 P=A”分类中有多条不同的记录;我们可以计算出这一类的记录数量,这个“记录数量”即为“属性 P=A”的一个度量值。假设我们的“属性 P”对应了上面这个表格里面的“客户类别”,“属性 P=A”代表着“客户类别是小型客户”,那么我们算出来的这个度量值应该填写在这个表里的什么位置?
答案是,目前的表格上没有能够填写的位置。因为上面这个表是关于“客户类别”和“日期”的交叉表。我们这个度量值的计算只考虑了“客户类别”,而没有考虑“日期”。所以说,我们算出来的这个数值应该是“周一到周日的所有客户数量的总和”,自然不会体现在具体某一天的度量值中。
为了把上面这个表填写上,我们需要把所有的数据条再按照“日期”来分个类,假设用“属性 Q”来代表日期,那么,“属性 P=A”且“属性 Q=周一”,再算出一个度量值,就能填写到第一行、第一列的格子里。
粒度 (Granularity)
粒度也就是“颗粒度”,指数据的 “粗细”,也就是我们看数据的精细程度的大小。粒度关注数据的详细程度或其分解的大小,通俗地讲,粒度关注“分析过程中将什么范围内的数据看作一个整体”
时间范围是常见的粒度。假设你正在分析一名客户的购物数据,年粒度看的是该客户一整年的购买情况,月粒度看的是该客户每个月的购买情况,日粒度看的是该客户每一天的购买情况。在年粒度情况下,观测数据时把“一整年”的数据都看作一个整体,月粒度则把“每个月”的数据看作一个整体;根据不同的数据需求制定不同的粒度要求,最终的观测值也会发生变化。
在下面一个例子里,有两个客户 A、B,我们需要观测的数据是“A 客户订单占比”,日粒度时,每天的观测数据是不同的,是每天的所有订单中,A 客户的订单占比;而周粒度时,我们在时间维度将这 7 天看成了一个整体,只会观测到一个数据,即这周的全部订单中,A 客户的订单占比。
| 粒度 | 日期 / 客户 / 订单数 | 客户A | 客户B | A 客户订单占比 |
|---|---|---|---|---|
| 日粒度 | 周一 | 1 | 0 | 100% |
| 周二 | 1 | 0 | 100% | |
| 周三 | 1 | 1 | 50% | |
| 周四 | 0 | 0 | – | |
| 周五 | 0 | 1 | 0% | |
| 周六 | 1 | 0 | 100% | |
| 周日 | 1 | 1 | 50% | |
| 周粒度 | 本周 | 5 | 3 | 62.5% |
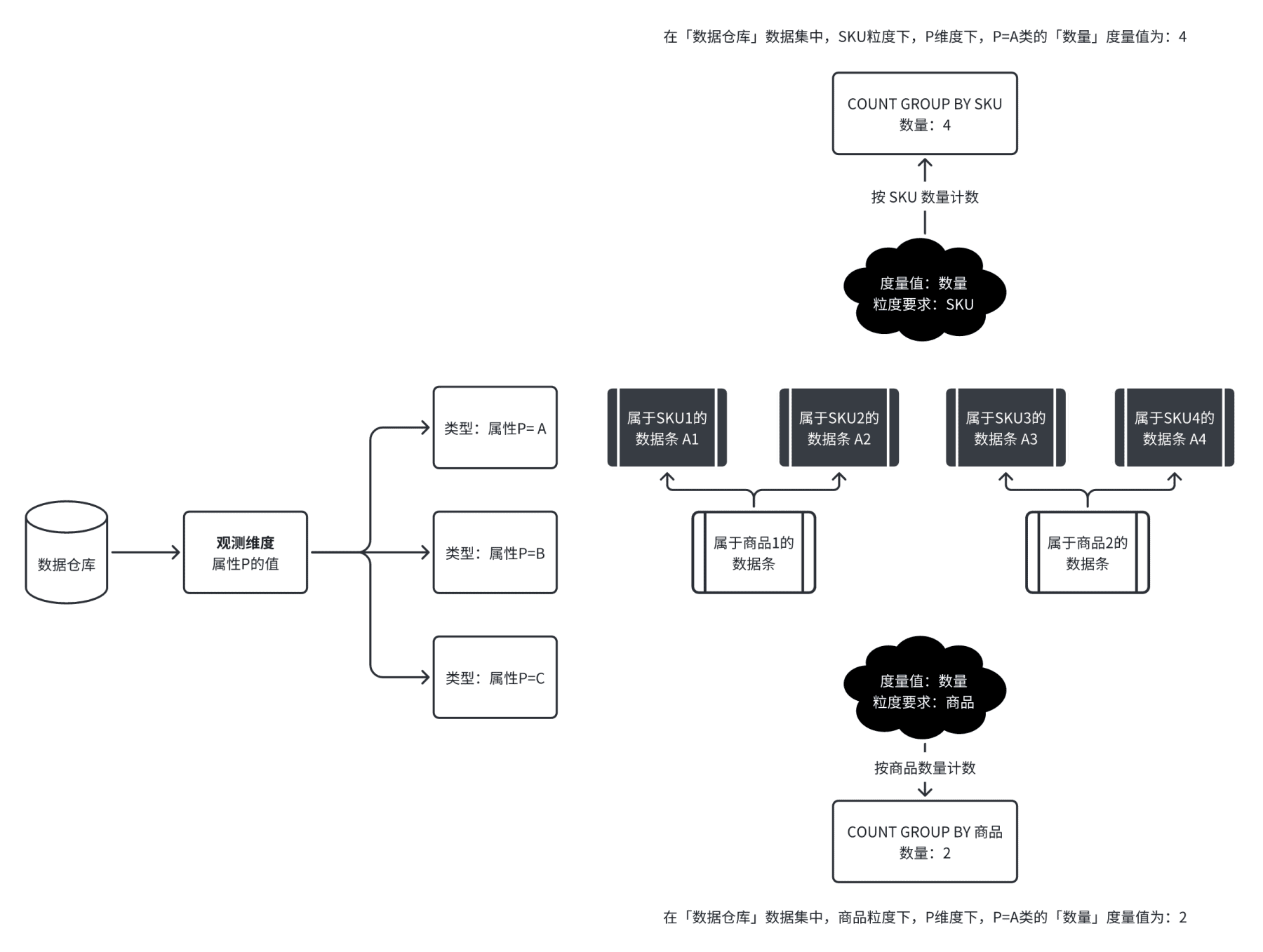
逻辑范围也是常见的粒度。刚刚的数据仓库里的数据,假设我们更改不同的粒度,会影响记录的条数变化与度量值的变化;例如之前的数据是“商品粒度”,也就是每条记录是“一个商品”,我们都知道,一个商品内可能有多个 SKU,代表着不同的规格,假设我们把粒度从“商品粒度”切换为“SKU 粒度”,那么新的数据模型里,每条记录是“一个 SKU”,对应的观测值“记录数量”也会发生变化
尺度 (Scale)
尺度的概念对比刚刚提到的维度、度量、粒度来说,相对独立。当我们在数据分析中提及“尺度”实际上是在谈论两方面的内容:一是数据的度量单位,二是数据的分类与测量标准。
首先,尺度与数据的度量单位密切相关。例如,在分析 GMV 时,我们可能会碰到不同的度量单位:
- 比如“千元”尺度下,10K表示10,000元;
- 或者在“百万元”尺度中,1M则代表1,000,000元。
然而,在数据科学的更广泛背景下,尺度不仅是一个简单的度量单位。它实际上是一个系统,用于描述数据的规模、大小和范围,从而对数据进行更为准确的分类和测量。
数据尺度的几种主要类型中,定类尺度(也叫做类别尺度或名义尺度),主要用于分类数据。就像给东西贴标签。例如,男性或女性、中国人或美国人;定序尺度(或称为等级尺度),能够表达数据之间的逻辑顺序或相对大小。一个常见的例子是 1-10 的满意度测量表。定距尺度不仅可以分类和排序数据,还可以确定数据之间的确切差距。例如,我们用定距尺度来测量温度或年龄。定比尺度除了具备上述所有特性,这种尺度还可以用来描述数据间的比例关系。比如,A 的收入是 B 的两倍。
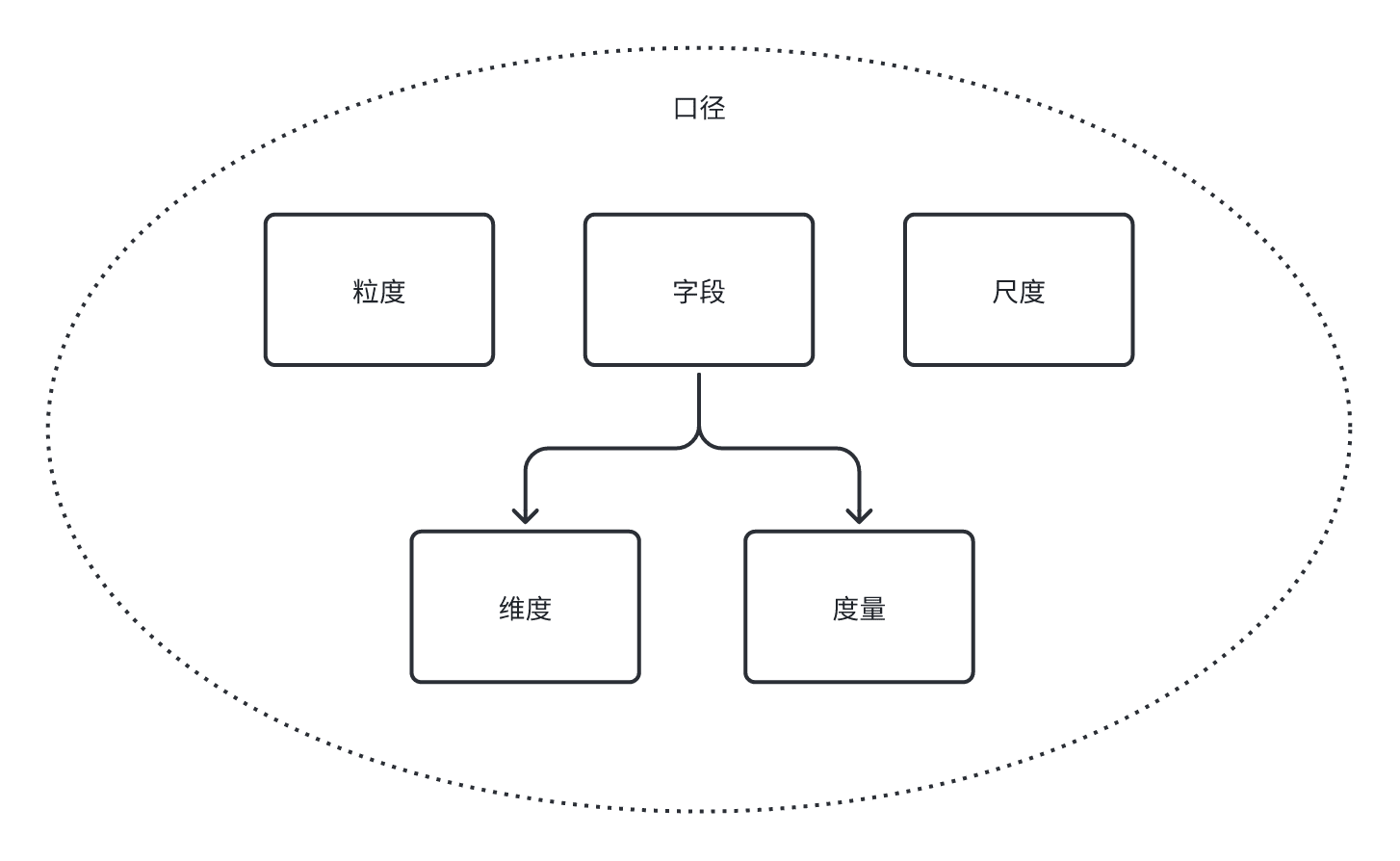
字段 (Field)
之所以把字段放在后面讲,是因为字段这个名词“本身蕴含的信息量较少”——度量可以是字段,维度也可以是字段;可以想象,一张表就像是一个大仓库,里面摆满了各种货物。这些货物就是数据,而每一个货架上的标签——告诉我们这是什么货物,就是“字段”。字段在数据库或数据表中储存信息的单位,你可以把它看作是表中的一列。字段产生在数据表诞生之初,我们在绘制数据表的时候,每行都是一个“数据条”,而相对应的,每一列都代表着一个字段——可能是“姓名”“身份证号”(属于索引),可能是“性别”“省份”(属于维度),也可能是“身高”“体重”“平均分数”(属于度量)。
所以,无论是维度还是度量,它们其实都是不同类型的字段。它们帮助我们理解数据,给数据分类,赋予数据意义。
而整个数据模型中的一切字段、维度、度量、粒度、尺度的定义,统称为“口径”。
口径 (Caliber)
口径其实是描述数据来源和计算方法的“规则”。不同的调查或统计方法得到的数据可能会有差异,比如,全国范围的普查得到的数据,和某个地区的小范围抽样调查得到的数据,它们的准确性和覆盖面是不一样的。而我们获取数据、处理数据、分析数据时候的需求不同,规则也不同。所以,选择合适的口径,就是确保数据准确性和可靠性的关键。
比如,我们可能有两种计算GMV的方法:
- 口径A:把所有的交易都算进去,不管是否退货。
- 口径B:只计算那些成功的、没有退货的交易。
那么通常“口径”包括哪些常见的内容?
我们可以这样完整记录一个口径:
基于“商品销售数据集”(数据集)进行分析,在“商品”为最小粒度下,区分不同的“价格区间”“带货渠道”维度下,“销售数量”的“总和”“最大值”“最小值”“平均值”。分析时间为最近 7 天,排除“促销类型”为“秒杀”的商品。
在这其中:“商品销售数据集”代表数据集,是我们数据分析的基石。“商品”是粒度,决定了我们后面的数据聚合计算方式是否正确。“价格区间”和“带货渠道”是维度,把所有的“商品”分成不同类型,也形成了我们最终产出的数据表的不同行。“销售数量总和”“销售数量最大值”“销售数量最小值”“销售数量平均值”则是聚合计算度量值,会对应不同的维度分类分别产生不同的值并记录在表格中。“分析时间”“促销类型不是秒杀”则是数据的筛选范围。
可以说,一次数据分析只有明确了上述全部内容,才有可能真正确定对应分析过程的实际含义。不同的口径,是不同的规则。协作讨论同一个问题时,通常需要使用相同的口径。
总结
至此,我们探讨了多个术语名词及其含义,“维度”、“粒度”、“尺度”和“口径”四个术语为数据分析的基石,它们在数据的组织、解读和应用中扮演着不可或缺的角色:
维度为我们提供了数据分类的视角,帮助我们按不同属性进行数据切分和观察。
粒度则决定了我们在数据探索中的深度,使我们能够根据需要查看数据的不同细节层次。
而尺度关注的是数据的度量单位与测量标准,为数据赋予了具体的意义和解读标准。
口径确保了数据的可靠性和一致性,它描述了数据的来源和处理方法,为数据分析结果提供了准确性和可信度的保证。
数据分析不仅仅是对数据的技术处理,更重要的是对数据的理解和解释。只有深入理解这些核心概念,我们才能够确保数据的正确性和可靠性,从而提供有价值的洞察和建议。


