- 类型:数据分析
- 使用方法:WordCloud PCA K-means
任务要求
利用python数据结构(list, dict, set等)完成简单的文本分析任务
1. 提供了「某电商平台」商品评论数据集,见资源/data/jd_comments.rar
2. 一行一条评论
3. 一行可以视为一个文档(document)
4. 读入所有文档并分词(需要jieba)
5. 过滤停用词,统计词频(停用词表自行检索并构建,如提供的 示例stopwords_list.txt)
6. 根据词频进行特征词筛选,如只保留高频词,删除低频词,并得到特征词组成的特征集
7. 利用特征集为每一条评论生成向量表示,可以是0,1表示 (one-hot)也可以是出现次数的表示
8. 计算一下不同评论之间的距离(自定义,如欧氏或余弦),找 到所有评论的“重心”或者所有文档中的代表性文档并输出原文。
9.(附加)能不能实现关键词的词云可视化
注意:通过函数进行封装,并在main函数中调用
任务划分
- 【读取数据】读取评论数据集;读取停用词
- 【文档分词】对每个文档进行分词,过滤停用词
- 【分词处理】统计词频,保留高频词,删除低频词,形成特征集
- 【数据处理】每条评论生成向量表示,计算评论距离,输出重心评论原文
- 【聚类分析】对特征集进行聚类分析
- 【词云可视】关键词词云可视化
STEP1 读取数据
最初编写代码为:
def get_comments(path):
"""
读取评论数据集,返回评论列表, 列表项为单条评论
:param path:
:return:
"""
comments_l = []
with open(path, 'r', encoding='utf-8') as comments_f:
for line in comments_f.readlines():
line = line.strip('\n')
comments_l.append(line)
return comments_l
def get_stopwords(path):
"""
读取停用词文档,返回停用词集合
:param path:
:return set(stopwords_l):
"""
stopwords_l = []
with open(path, 'r', encoding='utf-8') as stopwords_f:
for line in stopwords_f.readlines():
line = line.strip('\n')
stopwords_l.append(line)
return set(stopwords_l)
后发现二者高度一致,更改为:
def document_to_list(path):
"""
读取文档,按行划分,返回列表
:param path: 目标文档路径
:return doc_l: 文档内容列表
"""
print("正在将%s转换为文本列表, 请稍等..." % path)
doc_l = []
with open(path, 'r', encoding='utf-8') as doc_f:
for line in doc_f.readlines():
line = line.strip('\n')
doc_l.append(line)
return doc_l
Ref.
https://blog.csdn.net/qq_38161040/article/details/88388123
https://blog.csdn.net/qq_37828488/article/details/100024924
STEP2 文档分词
def cut_words(docs, stopwords):
"""
给出语句列表和停用词集合,使用 jieba 分词,返回分词列表
:param docs: 语句列表, 即分词操作的目标列表
:param stopwords: 停用词集合
:return wordlist: 分词后列表
"""
print("即将开始分词...")
wordlist = []
for doc in docs:
for word in jieba.lcut(doc):
if word not in stopwords:
wordlist.append(word)
return wordlist
Ref.
https://github.com/fxsjy/jieba
https://www.cnblogs.com/python-xkj/p/9247265.html
STEP3 分词处理
对分词结果进行处理,包括:统计词频,保留高频词,删除低频词,形成特征集
STEP3.1 统计词频并提取高频词
def word_freq(wordlist, topn):
"""
统计 wordlist 分词列表中前 topn 项目高频词,并返回特征集列表
:param wordlist: 分词列表
:param topn: 高频词数目限制
:return freq_word_list: 词频列表
:return freq_word_top: 高频词列表
"""
print("即将统计词频...")
freq_word_list = collections.Counter(wordlist)
freq_word_topn = freq_word_list.most_common(topn)
print("得到的特征集是:", freq_word_topn)
return freq_word_list, freq_word_topn
STEP3.2停用词的调整
设置topn = 80运行后,发现高频词结果如下:
[(' ', 1516), ('很', 1073), ('好', 635), ('不错', 451), ('还', 379), ('买', 366), ('电脑', 332), ('不', 323), ('都', 307), ('非常', 297), ('没有', 236), ('速度', 234), ('客服', 187), ('问题', 186), ('没', 185), ('开机', 183), ('京东', 180), ('满意', 176), ('感觉', 166), ('快', 164), ('说', 156), ('很快', 149), ('收到', 147), ('上', 137), ('东西', 135), ('系统', 133), ('看', 129), ('真的', 128), ('使用', 126), ('键盘', 118), ('喜欢', 115), ('包装', 113), ('送', 113), ('高', 112), ('有点', 111), ('挺', 106), ('后', 105), ('比较', 105), ('hellip', 105), ('外观', 104), ('会', 103), ('再', 103), ('游戏', 101), ('效果', 101), ('硬盘', 100), ('物流', 98), ('价格', 97), ('快递', 97), ('屏幕', 97), ('大', 94), ('性能', 93), ('跑', 90), ('机器', 88), ('流畅', 88), ('分', 88), ('性价比', 87), ('一下', 87), ('运行', 85), ('才', 85), ('安装', 84), ('购买', 82), ('评价', 82), ('值得', 81), ('玩', 81), ('下', 80), ('鼠标', 80), ('方便', 78), ('不是', 78), ('一次', 78), ('知道', 77), ('配置', 77), ('总体', 77), ('耐心', 76), ('卖家', 74), ('好评', 74), ('现在', 73), ('笔记本', 73), ('特别', 73), ('小', 69), ('推荐', 69)]
能够发现仍然存在相当一部分无意义词语,因此需要更新停用词列表,增加停用词见右栏:
发现最开始分词结果出现
hellip,实际为原始数据集中的&hellip,实际为HTML中省略号实体
对停用词列表进行调整后,再次设置topn = 80,高频词结果如下:
[('好', 635), ('不错', 451), ('电脑', 332), ('没有', 236), ('速度', 234), ('客服', 187), ('问题', 186), ('开机', 183), ('京东', 180), ('满意', 176), ('快', 164), ('很快', 149), ('系统', 133), ('使用', 126), ('键盘', 118), ('喜欢', 115), ('包装', 113), ('高', 112), ('比较', 105), ('外观', 104), ('会', 103), ('再', 103), ('游戏', 101), ('效果', 101), ('硬盘', 100), ('物流', 98), ('价格', 97), ('快递', 97), ('屏幕', 97), ('大', 94), ('性能', 93), ('跑', 90), ('机器', 88), ('流畅', 88), ('性价比', 87), ('运行', 85), ('安装', 84), ('购买', 82), ('评价', 82), ('值得', 81), ('玩', 81), ('鼠标', 80), ('方便', 78), ('配置', 77), ('耐心', 76), ('卖家', 74), ('好评', 74), ('笔记本', 73), ('特别', 73), ('小', 69), ('推荐', 69), ('第一次', 68), ('装', 67), ('服务', 64), ('质量', 64), ('固态', 63), ('内存', 63), ('很多', 63), ('软件', 62), ('清晰', 61), ('机子', 60), ('办公', 59), ('声音', 58), ('购物', 58), ('需要', 58), ('赞', 58), ('几天', 58), ('发货', 53), ('朋友', 53), ('散热', 53), ('店家', 52), ('态度', 52), ('完美', 52), ('做工', 51), ('款', 50), ('好看', 50), ('支持', 50), ('玩游戏', 50), ('直接', 49), ('下单', 49)]
至此,关键词集,即后续统计分析的特征集构建完毕。用于后续
STEP3.3 获得词袋
def get_word_pack(wordlist):
"""
在特征集的基础上获得词袋,用于后续统计分析
:param wordlist: 特征集列表,其元素为集合
:return wordpack: 特征词列表
"""
print("即将获得词袋...")
wordpack = []
for wordset in wordlist:
wordpack.append(wordset[0])
print("提取的特征词是:", wordpack)
return wordpack
Ref.
https://docs.python.org/3/library/collections.html
https://www.cnblogs.com/dianel/p/10787693.html
STEP4数据处理
STEP4.1 为每条评论生成向量表示
A. one-hot 方法
def get_onehot_matrix(comments_l, word_p):
"""
根据评论列表和词袋输出基于 onehot 方法的矩阵
:param comments_l: 每个元素是一条评论的列表
:param word_p: 特征词词袋
:return matrix: 行数为评论数,列数为词袋数的矩阵
"""
matrix = np.zeros((len(comments_l), len(word_p)))
for comment in comments_l:
for word in word_p:
if word in comment:
matrix[comments_l.index(comment)][word_p.index(word)] = 1
# 考虑评论列表项和词袋项均不重复,可以使用 index() 方法
return matrix
B. 频数方法
def get_freq_matrix(comments_l, word_p):
"""
根据评论列表和词袋输出基于频数统计的矩阵
:param comments_l: 每个元素是一条评论的列表
:param word_p: 特征词词袋
:return matrix: 行数为评论数,列数为词袋数的矩阵
"""
matrix = np.zeros((len(comments_l), len(word_p)))
for comment in comments_l:
for word in word_p:
matrix[comments_l.index(comment)][word_p.index(word)] = comment.count(word)
return matrix
STEP4.2 确定向量重心,计算各向量与重心距离
def get_distance_list(matrix):
"""
根据特征向量矩阵计算重心,根据重心计算各向量与重心的距离
:param matrix: 特征向量矩阵
:return:
"""
# 首先确定重心
print("正在计算特征词数量为%d的所有向量的重心..." % len(matrix[0]))
count = [0] * len(matrix[0])
for row in range(0, len(matrix)):
for column in range(0, len(matrix[0])):
count[column] += matrix[row][column]
for column in range(0, len(count)):
count[column] = count[column] / len(matrix)
gravity_center = count
print("所有特征向量的重心为: %s\n" % gravity_center)
# 计算各向量与重心的距离
dis_list = []
for row in range(0, len(matrix)):
dis = np.sqrt(np.sum(np.square(gravity_center - matrix[row])))
dis_list.append(dis)
return gravity_center, dis_list
STEP4.3 获取最近、最远评论
def get_gc_comment(dislist):
gc_index = dislist.index(min(dislist))
gc_indexx = dislist.index(max(dislist))
print("距离重心最近的评论编号是: " + str(gc_index+1) + ", 其内容为: ")
print(comments_list[gc_index])
print("----其也可视为所有评论的重心。\n")
print("距离重心最远的评论编号是: " + str(gc_indexx+1) + ", 其内容为: ")
print(comments_list[gc_indexx])
A. one-hot方法
------使用 onehot 方法------ 正在计算特征词数量为80的所有向量的重心... 所有特征向量的重心为: [0.6087824351297405, ..., 0.04890219560878244] 距离重心最近的评论编号是: 337, 其内容为: 首先很抱歉我用了这么久才来晒图,就一句话,太好用了!我用过罗技上千元的也不如这个好!配上外星人,感觉真的很好啊! ----其也可视为所有评论的重心。 距离重心最远的评论编号是: 222, 其内容为: 我对电脑有一些研究,以前我是用雷神的,虽然不差但是不是很满意。机械师炫酷的外形吸引了我,背光键盘,银色外形,反正孤陋寡闻的我是没有见过比机械师更炫酷的笔记本?,外星人?我也在朋友那里用过,是好但是外形的炫酷还是不及机械师,对于一般人来说也浪费配置,这是我个人的想法?。买电脑看重的无非是质量和运行速度,机械师在这两个方面也是做得非常好,我第一次开机只用了一秒,用了几天开机从来没有超过4秒,我买这个电脑是为了玩LOL的,给我的感觉很好,第一次在笔记本上打排位还超神啦?,玩英LOL这种小内存游戏无比流畅,玩虐杀原形这种大型游戏也是通行无阻。我想在座的各位想买游戏本的大部分追求外观的炫酷和游戏的极速体验,机械师在这个方面真心不错。智能双风扇涡轮散热,1920.1080分辨率,非常不错,鲁大师跑分是182740。客服“神奇先生”,也是非常热情的回答我各种问题,很专业也很有耐心,还给我免费装了win10系统,必须给五个赞?,哈哈。然后送货也很快,我在上海,一天就到啦,当场验货,很有保障。可能在座的各位觉得我在吹牛,但是毕竟6600的价格,一分钱一分货,有这么多优点也是合乎情理的。
B.频数方法
------使用频数方法------ 正在计算特征词数量为80的所有向量的重心... 所有特征向量的重心为: [1.0728542914171657, ..., 0.05089820359281437] 距离重心最近的评论编号是: 861, 其内容为: 非常非常非常好!!!…………………………………………………… ----其也可视为所有评论的重心。 距离重心最远的评论编号是: 916, 其内容为: 真的很不错真的很不错真的很不错真的很不错真的很不错真的很不错真的很不错真的很不错真的很不错真的很不错真的很不错真的很不错真的很不错
运行截图

Ref.
https://blog.csdn.net/Robin_Pi/article/details/103732978
https://blog.csdn.net/weixin_43238031/article/details/120064530
https://www.cnblogs.com/djdjdj123/p/12584130.html
https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/
STEP5 聚类分析
STEP5.1 PCA降维
首先通过PCA降维到二维,判断两种向量处理方法哪一种方差较大,利于进行聚类分析。
def get_pca(matrix, n, title):
"""
进行 PCA 降维
:param matrix: 需要降维的矩阵
:param n: 降维主成分数量
:return:
"""
pca = PCA(n_components=n)
pca_matrix = pca.fit_transform(matrix)
# 绘图
plt.rcParams['font.sans-serif'] = ['KaiTi_GB2312'] # 步骤一(替换sans-serif字体)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.set_title(title)
plt.scatter(pca_matrix[:, 0], pca_matrix[:, 1], c='m', marker='*')
plt.show()
return
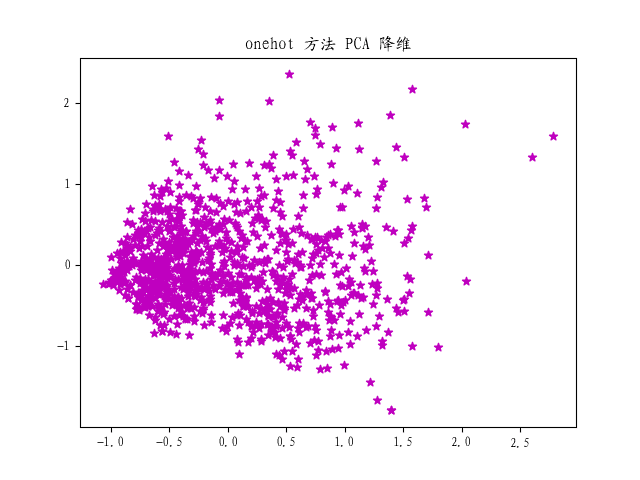
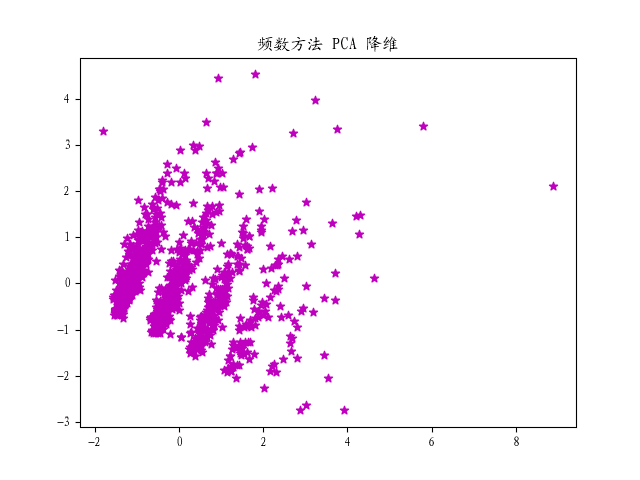
在此选用频数法进行后续的聚类分析。
👨🏻🎓如何判断两种方式哪种更适合后续分析?频数方法为何会有明显的分离?
STEP5.2 K-Means 聚类
中心数判断
首先绘制畸变曲线,确定聚类中心数
def kmeans_test(pca_matrix, k):
"""
确定聚类中心数
:param pca_matrix: 聚类数据集
:param k: 中心数最大值
:return:
"""
clf_inertia = [0.] * k
for i in range(1, k + 1, 1):
clf = KMeans(n_clusters=i, max_iter=300)
s = clf.fit(pca_matrix)
clf_inertia[i - 1] = clf.inertia_
# 畸变程度曲线
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.set_title("KMeans中心数变化畸变曲线")
plt.plot(np.linspace(1, k, k), clf_inertia, c='b')
plt.xlabel('center_num')
plt.ylabel('inertia')
plt.show()
return
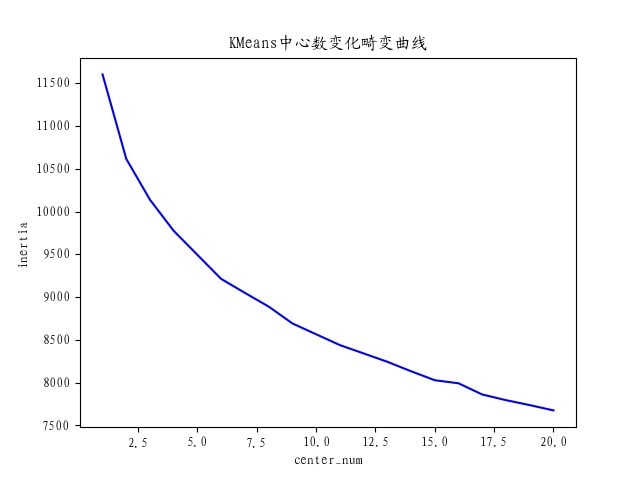
根据畸变曲线,确定k=6
评论分组
def kmeans(pca_matrix, k, mat):
clf = KMeans(n_clusters=k)
clf.fit(pca_matrix)
fig = plt.figure()
an = fig.add_subplot(111)
an.set_title("PCA 降维聚类分析图")
color = ['r', 'y', 'b', 'g', 'c', 'm']
for i in range(k): # 对每一类聚类分别进行处理
comment_if = clf.labels_ == i # 获得每个元素所在簇的列表 comment_in 判断是否满足 i 类
xs = pca_matrix[comment_if, 0]
ys = pca_matrix[comment_if, 1]
plt.scatter(xs, ys, c=color[i], marker='.')
plt.legend(["第1组", "第2组", "第3组", "第4组", "第5组", "第6组"])
plt.show()
comment_ll = {0: [], 1: [], 2: [], 3: [], 4: [], 5: []} # 每类的评论
vector_ll = {0: [], 1: [], 2: [], 3: [], 4: [], 5: []} # 每类的评论对应的向量
# 最初尝试将两个变量设置为嵌套表格形式,但最终失败
comment_in = clf.labels_
print(comment_in)
for j in range(len(comment_in)):
no = comment_in[j]
print("第%s条评论落在第%s组" % (j + 1, no + 1))
comment_ll[no].append(comment_list[j])
vector_ll[no].append(mat[j])
for m in range(k):
# 分组计算重心并输出各组的重心评论
print("\n------对于第%d组------\n" % (m + 1))
get_k_comment(comment_ll[m], vector_ll[m])
return
- 最开始尝试将
comment_ll, vector_ll两个变量设置为嵌套表格形式,但最终失败,原因尚不明确
👨🏻🎓发现每次运行的结果都是不同的,这是由于K-Means的方法随机选择起始点而决定的。

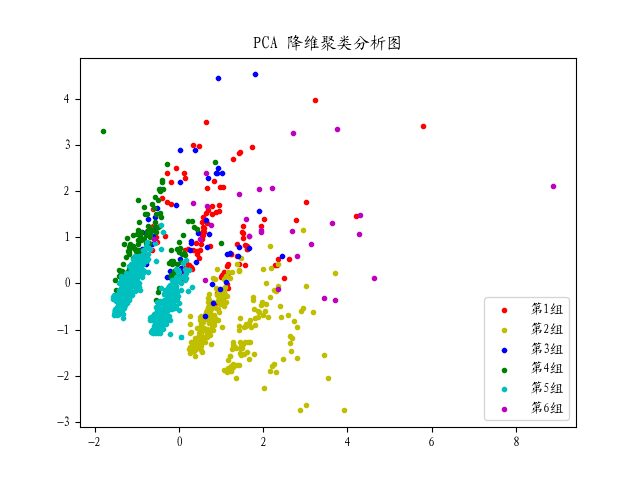
每组重心
def get_k_comment(comment_l, vector_l):
count = [0] * len(vector_l[0])
for row in range(0, len(vector_l)):
column: int
for column in range(0, len(vector_l[0])):
count[column] += vector_l[row][column]
for column in range(0, len(count)):
count[column] = count[column] / len(vector_l)
gravity_center = count
print("本组所有特征向量的重心为: %s\n" % gravity_center)
# 计算各向量与重心的距离
dislist = []
for row in range(0, len(vector_l)):
dis = np.sqrt(np.sum(np.square(gravity_center - vector_l[row])))
dislist.append(dis)
gc_index = dislist.index(min(dislist))
print("距离重心最近的评论编号是: " + str(gc_index + 1) + ", 其内容为: ")
print(comment_l[gc_index])
print("----其也可视为本组所有评论的重心。\n")
return

------对于第1组------ 本组所有特征向量的重心为: [0.3047619047619048, ..., 0.047619047619047616] 距离重心最近的评论编号是: 17, 其内容为: 首发入的,晚上下单,早上就到了,速度挺快的,以前一直用青轴,这次换个银轴试试,打字也挺舒服的,就是左边6个宏键还要慢慢适应,经常容易按错键,手托不错,柔软有弹性,送的金色键帽也不错 ----其也可视为所有评论的重心。 ------对于第2组------ 本组所有特征向量的重心为: [0.796875, ..., 0.03125] 距离重心最近的评论编号是: 3, 其内容为: 东西包装完好,打开以后发现买家还放了泡沫板,真是很贴心,设置也很简单,地下带轮子,方便移动,也可以安装到墙上,挺不错的, ----其也可视为所有评论的重心。 ------对于第3组------ 本组所有特征向量的重心为: [1.3153153153153154, ..., 0.15315315315315314] 距离重心最近的评论编号是: 20, 其内容为: 这送货速度太快了,昨天23点下的订单一早上就送来,感谢京东快递小哥,感谢东哥这么好的企业、我也晒个单吧 ----其也可视为所有评论的重心。 ------对于第4组------ 本组所有特征向量的重心为: [2.5281385281385282, ..., 0.04329004329004329] 距离重心最近的评论编号是: 73, 其内容为: 首先很抱歉我用了这么久才来晒图,就一句话,太好用了!我用过罗技上千元的也不如这个好!配上外星人,感觉真的很好啊! ----其也可视为所有评论的重心。 ------对于第5组------ 本组所有特征向量的重心为: [0.4190064794816415, ..., 0.03023758099352052] 距离重心最近的评论编号是: 52, 其内容为: 从2017年心仪很久的线程撕裂者,攒钱准备买1950x,一直等到了二代线程撕裂者发布,RTX发布,双11终于狠下心入手了,到手很有仪式感,等待x72海妖正式撕裂! ----其也可视为所有评论的重心。 ------对于第6组------ 本组所有特征向量的重心为: [2.4285714285714284, ..., 0.10714285714285714] 距离重心最近的评论编号是: 7, 其内容为: 某东日常标错价,玩家心里乐开花23333333。好了不闹了,我买的是I5 7300HQ,8GB内存,128+1T和1050GDR5的版本,官网价5999,京东价5499我顿时虎躯一震。。好嘛,日常任务(1/1)了?赶紧吃进啊,洒家也是戴尔情怀脑残粉了,基本上属于晚期没救了电也电不回来,吃药?没药可吃的戴尔粉了。从高中虐杀了latitudeX1到大学搞酥了老INS14R,再到后来这个本之前的那个戴尔Insprion14RD-5421触控本。。。。本来是换了个硬盘,结果5421出现了主板7声的毛病。没救了,再加上用了4年,性能已然已经落伍了,最主要的是显卡基本上属于亮游戏的水平了。。。。。哎等会。。貌似扯远了啊。。。 这个电脑可以这么说,是我终于不后悔的一次选择。为什么这么说?这价钱接近上船的价钱,但是整机外壳敦实的吓人,外形骚到爆炸。黑加红,简直就是骚到不行。。三面大型的散热片带来的是无敌的散热(当然声音巨大这是问题),128GB+1T的存储空间要快速有快速要容量有容量。而且尺寸控制绝对是非常好的,15.6寸的屏幕尺寸,整机只比INS14-5421这个14寸本长4公分高不到2公分厚度竟 ----其也可视为所有评论的重心。
Ref.
https://zhuanlan.zhihu.com/p/30047153
https://blog.csdn.net/qiu931110/article/details/68130199
https://cloud.tencent.com/developer/article/1761532
https://blog.csdn.net/qq_34159047/article/details/107130643
https://blog.csdn.net/xiaoyi_zhang/article/details/52269242
https://blog.csdn.net/zhubao124/article/details/80719306
STEP6 词云可视
def wordcloud(wordlist):
"""
输入高频词频对列表[( , ), ..., ( , )],转换为键值对,并绘制词云图
:param wordlist:
:return:
"""
word_dict = dict(wordlist)
img = Image.open("0_res/1.png")
img_mask = np.array(img) # 将图片转换为数组
wc = WordCloud(font_path="/System/Library/Fonts/Hiragino Sans GB.ttc",
mask=img_mask,
background_color="white", max_words=300,
max_font_size=200, random_state=35)
image_colors = ImageColorGenerator(img_mask)
wc.generate_from_frequencies(word_dict)
plt.imshow(wc.recolor(color_func=image_colors), interpolation='bilinear') # -------显示词云
plt.axis('off') # ------关闭坐标轴
plt.show() # -----------显示图像
return

Ref.
https://www.jianshu.com/p/2052d21a704c
https://zhuanlan.zhihu.com/p/242740731
https://blog.csdn.net/qq_43328313/article/details/106824685
库管理
import collections # ------------------ 用于词频统计 import jieba # ------------------------ 用于分词 import matplotlib.pyplot as plt # ----- 用于绘图 import numpy as np # ------------------ 用于 np 数据处理 from PIL import Image # --------------- 用于词云图读取图片 from sklearn.decomposition import PCA # 用于 PCA 分析 from sklearn.cluster import KMeans # -- 用于 KMeans 聚类分析 from wordcloud import ImageColorGenerator # -------------------------------------- 用于词云图设置图片颜色 from wordcloud import WordCloud # ----- 用于词云图
main()函数
def main():
global comment_list
comment_list = document_to_list("0_res/jd_comments.txt")
stopwords_set = document_to_list("0_res/stopwords_list.txt")
word_list = cut_words(comment_list, stopwords_set)
word_list_freq, word_list_top = word_freq(word_list, topn=80)
word_pack = get_word_pack(word_list_top)
wordcloud(word_list_top)
# # 使用 onehot 方法
# print("\n------使用 onehot 方法------\n")
# matrix1 = get_onehot_matrix(comment_list, word_pack)
# gravity_c1, dis_list1 = get_distance_list(matrix1)
# get_gc_comment(dis_list1)
# 使用频数方法
print("\n------使用频数方法------\n")
matrix2 = get_freq_matrix(comment_list, word_pack)
gravity_c2, dis_list2 = get_distance_list(matrix2)
get_gc_comment(dis_list2)
# # 使用 onehot 方法进行聚类分析
# onehot_pca = get_pca(matrix1, 0.8, "onehot 方法 PCA 降维 (80%)")
# kmeans(onehot_pca, 6)
# 使用频数方法进行聚类分析
freq_pca = get_pca(matrix2, 0.8, "频数方法 PCA 降维 (80%)")
kmeans_test(freq_pca, 20)
kmeans(freq_pca, 6, matrix2)
return




感谢学长,我已经学会了!这篇文章真的救急了!